
수학 없이 시작하는 인공지능 첫걸음: 기초부터 최신 트렌드까지 강의 | 김지훈 - 인프런
김지훈 | 수학 수식과 같이 어려운 내용은 덜어내어, 가벼운 마음으로 AI에 대한 전반적인 지식을 얻을 수 있는 강의입니다., 인공지능이 대체 뭐길래? 여러분의 궁금증, 정말 쉽게 해결해드릴게
www.inflearn.com
인프런에 있는 '수학 없이 시작하는 인공지능 첫걸음'을 듣고 요약해보는 시리즈입니다.
1강 : AI 역사
인공지능 : 사람의 지적 능력과 기술을 프로그래밍을 통해 구현하는 기술
머신러닝 : 데이터를 기반으로 알고리즘(모델) 학습하여 해당 분야 문제들을 추론하는 기술
딥러닝 : 머신러닝 분야, 인공 신경망을 활용한 머신러닝의 일종 (Artificial Neural Network)
AI 흥망성쇠
: AI 붐은 총 3차례로 이루어지는데, 중간 중간에 암흑기를 가졌다.
- 1차 AI 붐 : AI 개념 제시
- 1번째 암흑기
- 2차 AI 붐 : 전문가 시스템
- 2번째 암흑기
- 3차 AI 붐 : 머신러닝/딥러닝
퍼셉트론
- 인간의 뉴런을 따라하는 특징을 가진다. 특정 입력을 가중치로 바꾸고 가중치를 활성화 함수로 계산해 일정 수치가 넘어가면 …?
- 선형적인 것만 해결이 가능함
- 비판이 제기됨
2차 AI 붐
- 전문가 시스템의 등장
- 예시) AI 판사
- 새로운 사건이 들어오면 과거 데이터로 판단한다. 기계가 사람을 대신할 수 있게 됨
- Vanishing Gradient 문제가 새롭게 등장함
- 제일 앞서 학습했던 데이터를 기계가 까먹어 학습이 제대로 안되는 현상
- 2번째 암흑기가 등장한다. 돈을 제일 많이 투자했지만 결과가 안나옴
- 예시) AI 판사
- 다층 퍼셉트론 : 여러개를 엮어 선형-비선형 문제를 해결
- 다층 퍼셉트론 + 역전파 알고리즘을 활용해 문제를 해결
- 4가지 이유로 3번째 AI붐이 발생한다.
- 하드디스크 비용이 줄었음
- 기존 인공신경망 알고리즘이 개선됨
- Vanishing Gradient 문제가 해결됨
- Deep 개념의 등장
- 인공신경망 대체 단어인 'Deep Belief'의 등장
- AI 가능성을 믿고 끝까지 연구한 연구진
- 아이들이 사물을 배우는 방법에서 착안해 이미지넷 프로젝트가 시작됨
- 2만 2천개의 클래스와 총 1500만장의 이미지 데이터셋을 구축함
- 클래스는 한 카테고리를 의미함
- ILSVRC라는 대회에서 1,000개의 클래스를 이용해 모델 성능이 높은 것을 뽑음
- 2011년, Shallow 모델, 오답률 28.2%
- 2012년, AlexNet 모델, 오답률 16.4% 성능이 확 오름
- 2013년, ZFNet 모델, 오답률 12%
- 2014년, VGG 모델, 오답률 7.3%
- 2015년, ResNet 모델, 오답률 3.56% => 인간보다 높은 성능을 보이기 시작함
- 2016년, GoogLeNet-V4 모델, 오답률 3%
- 2017년, SENet 모델, 오답률 2.3% => 대회 종료
- 이후 캐글의 등장, 알파고가 등장
- 기계가 최초로 인간을 이김, AI의 글로벌화가 시작됨
- 이후 AI를 위해 노력한 사람들은 구글의 부사장, 구글 AI 센터 리더, 스탠포드 대학 교수가 됨
2강 : 판단 모델
판단 모델
- 데이터의 종류를 판단
- 학습법
- 사진이 고양이인지 판단하는 AI 모델
- 판단원리
- 학습을 통해 패턴을 찾아 문제에 적용함
- 학습 방식
- 수많은 데이터가 필요함
- 캐글의 경우
- 개, 고양이 데이터셋이 존재한다. 학습을 통해 모델이 해당 데이터 패턴을 찾는 것이 목적
- 패턴 찾기
- AI 모델이 스스로 수행
- 고양이 이미지의 경우, 고양이의 특징을 기반으로 학습한 뒤 새로운 고양이 이미지를 보고 고양이인지 AI 판단 모델이 스스로 판단을 진행함.
- 고양이의 동공, 눈동자 쉐입, 고양이 형상 순으로 판단함
- 판단모델의 대표적인 학습방법 2가지
- 지도학습
- 머신러닝의 대표적인 학습법, 데이터와 데이터에 대한 정답을 모델에게 함께 제공한 뒤 학습함
- 예시) 이상탐지, 공장 내부 불량품 검출, 은행 입출금 이상탐지, 이미지인식(객체/얼굴인식), 문자인식(OCR), 동영상인식(저작권 영상 감지), 자율주행, 주식, 경제 예측 등 (과거 데이터 기반 학습을 수행 후 미래를 예측)
- 수많은 문제와 정답을 함께 제공하여 문제를 데이터화하고 정답을 라벨링 한다.
- 특징을 스스로 학습
- 하지만 세상에 있는 대부분의 데이터는 정답이 없다. => 비지도 학습이 등장함
- 비지도학습
- 문제에서 스스로 패턴을 찾고 주어진 문제들을 클러스터링함
- 문제만 주고 학습을 진행시키므로 라벨이 존재하지 않음
- 예시) 추천시스템, 타겟마케팅
- 기가막히게 잘하는 기업들 : 넷플릭스, 유튜브, 스포티파이, 클러스터링 기반 서비스, 메타
- 자연스럽게 내 취향의 무언가를 추천해줌
- 이미 클러스터링 당하고 있을지도 모름. 궁금하다면 크롬 프로필이나 블로그 개인 맞춤 광고를 확인해볼것
- 번외) 강화학습
- 스키너의 쥐 실험
- 쥐가 페달을 누르도록 학습시키는 먹이 실험이다
- 보상을 통한 학습으로 각인시킨다
- 에이전트가 특정 행동을 하면 환경이 변하고 학습이 주어진다.
- 특정 환경에서 처벌과 보상을 지속적으로 주면서 원하는 결과로 이끌어감
- 대표 예시는 알파고가 있다
- 스키너의 쥐 실험
- 지도학습
3강 : 생성모델
- 세상에 없는 데이터를 생성함
- 세가지 특징
- 거대한 모델
- 20년도 이전 : 100억개 내외의 파라미터
- GPT-3 : 1750억개의 파라미터
- 엄청난 수의 데이터 셋
- DALL-E : 2억 5천만개
- 이미지-텍스트 pair 데이터
- 텍스트와 이미지의 상관관계로 프롬프트를 통해 이미지를 생성함
- GPT-3
- NovelAI
- GPT-3 기반
- 문장을 쓰면 소설을 작성해줌
- 애니메이션 AI도 만들었음
- 네이버-painter : 와이어프레임에 자동으로 색칠해줌
- Danbooru : 제 3자가 불법으로 이미지들을 업로드하고 이미지 태깅한다.
- Novel AI에서 여기 불법 업로드된 이미지를 가져가 학습할 경우 문제가 발생함
- Prompt Engineering
- AI에게 명령을 내림
- "단계별로 생각해보자"라고 명령시 정확도가 높아진다는 연구 결과가 있음
- 기획자, 일러스트렝터는 프롬프트 엔지니어링을 잘하면 좋을 것 => 새로운 비즈니스
- 거대한 모델
4강 : AI 서비스 라이프 사이클
음성 인식 AI 스피커의 라이프 사이클을 그려보자.
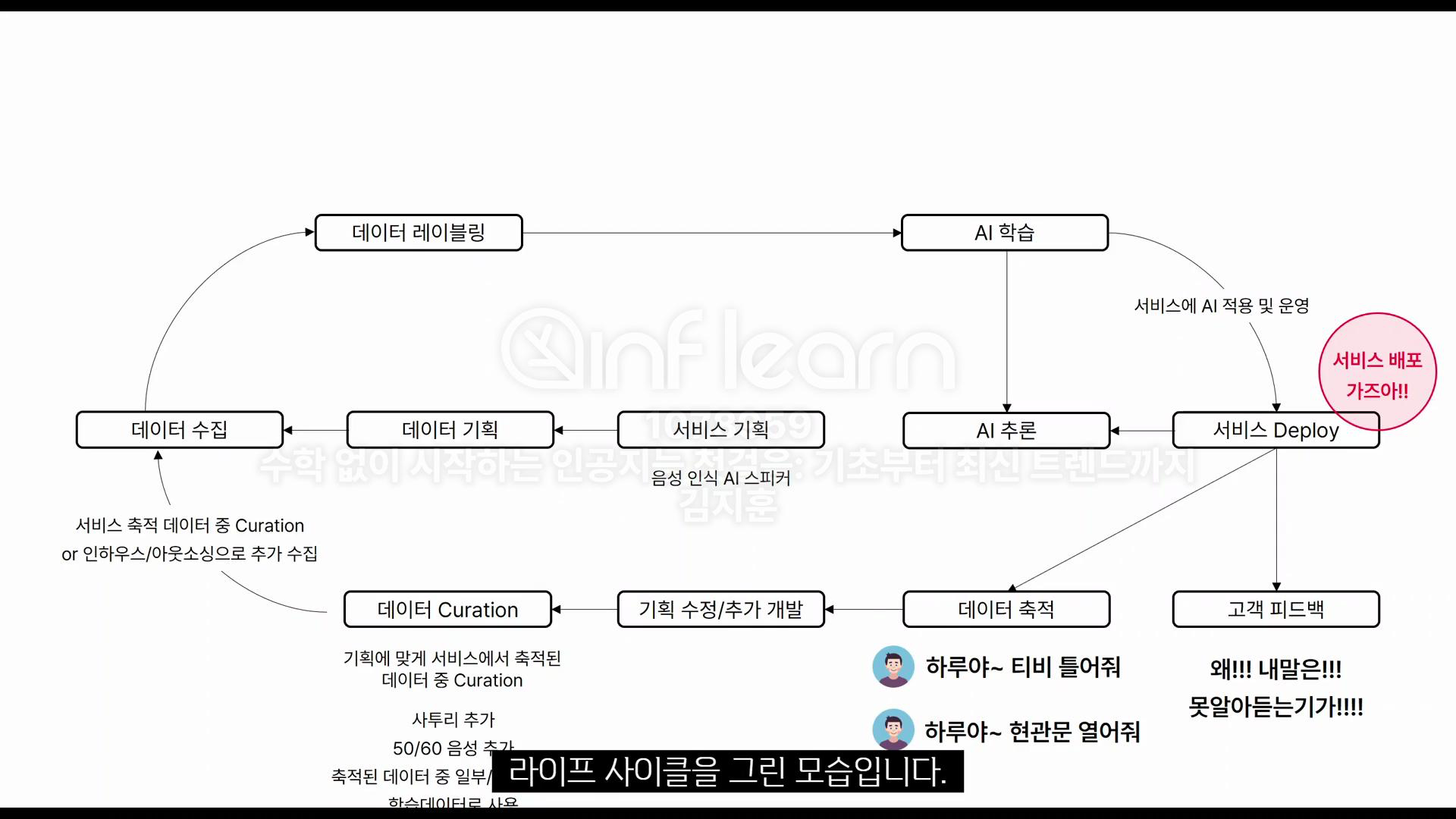
- 서비스 기획
- 음성으로 티비를 켜준다
- 음성인식이 필요하다 -> AI의 필요성
- 데이터 기획
- 수집 타겟
- 10대 ~ 40대 남성 및 여성
- 표준 말투 사용자
- 10초 내외의 문장
- 법적 요건을 검토 (개인 정보 보호법)
- 데이터 수집 방법
- 성우 구인
- 일반인 구인
- 유튜브
- 네이버 동영상
- 내부 직원
- 방음실/가정환경 등 다양한 환경에서 수집
- 데이터 레이블링
- 음성에 대한 타이핑을 통해 정답을 달아주는 것
- 예) "오늘도 고생하셨습니다."
- 문제 영상과 정답 자막을 통해 AI가 학습함 => 판단모델/지도학습
- 사람이 직접 음성 텍스트 작업을 진행하므로 정확도가 높음
- 음성에 대한 타이핑을 통해 정답을 달아주는 것
- AI 학습
- 데이터를 활용해 AI 모델 개발을 수행함
- 최신 논문 분석을 통해 설계를 진행
- 서비스 Deploy
- 서비스에 AI 적용 및 운영
- 데이터 축적
- 여기서부터 문제가 기하급수적으로 발생함
- 고객 피드백
- 고객에게 "왜 내말은 잘 못 알아듣죠?" 라는 피드백이 올 수 있음
- 이럴땐 "죄송합니다, 업데이트하겠습니다."라고 공지한다
- 이때부터 고객 데이터가 축적된다. 물론 고객에게 데이터를 제공받겠다는 약관을 동의받아야함
- 고객 데이터를 기반으로 기획을 수정하고 필요로 보이는 기능들을 추가 개발한다
- 데이터 큐레이션
- 기획에 맞게 서비스에 축적된 데이터 중에 큐레이션을 진행함
- 사투리를 추가하고 50대~60대의 음성을 추가함
- 경상도, 전라도 음성을 추가하고 괜찮은 데이터만 학습 데이터로 재사용한다
- 데이터 재수집
- 서비스 축적 데이터 중 Curation 또는 인하우스/아웃소싱 등으로 추가적으로 음성 데이터를 수집 -> 이후 무한반복한다.
- 데이터 레이블링 업체
- 주요 업무 : 데이터 레이블링 / 데이터 수집 / 데이터 기획 및 법적 요건 검토
- 수집 데이터를 레이블링 후, 고객에게 데이터를 납품한다
- AI 모델 중심 -> 데이터 중심 접근 방법으로 변환이 필요함
- AI 모델의 성능을 높이기 보다 데이터 레이블링을 통한 정확도 높임이 필요함
- 높은 정확도의 모델도 중요하지만 AI 학습을 위한 양질의 데이터가 더 중요
- 데이터 사이언티스트, 데이터 분석가, 데이터 엔지니어의 등장
- 데이터 기반 비즈니스로 인한 직군의 등장
- 역할 : 데이터 수집 / 데이터 기획 / 서비스 기획 / 데이터 Curation / 기획 수정 / 추가 개발 / 데이터 축적 / 고객 피드백
- 데이터 기반의 비즈니스 견적을 확인
- 수집 타겟
데이터 사이언티스트
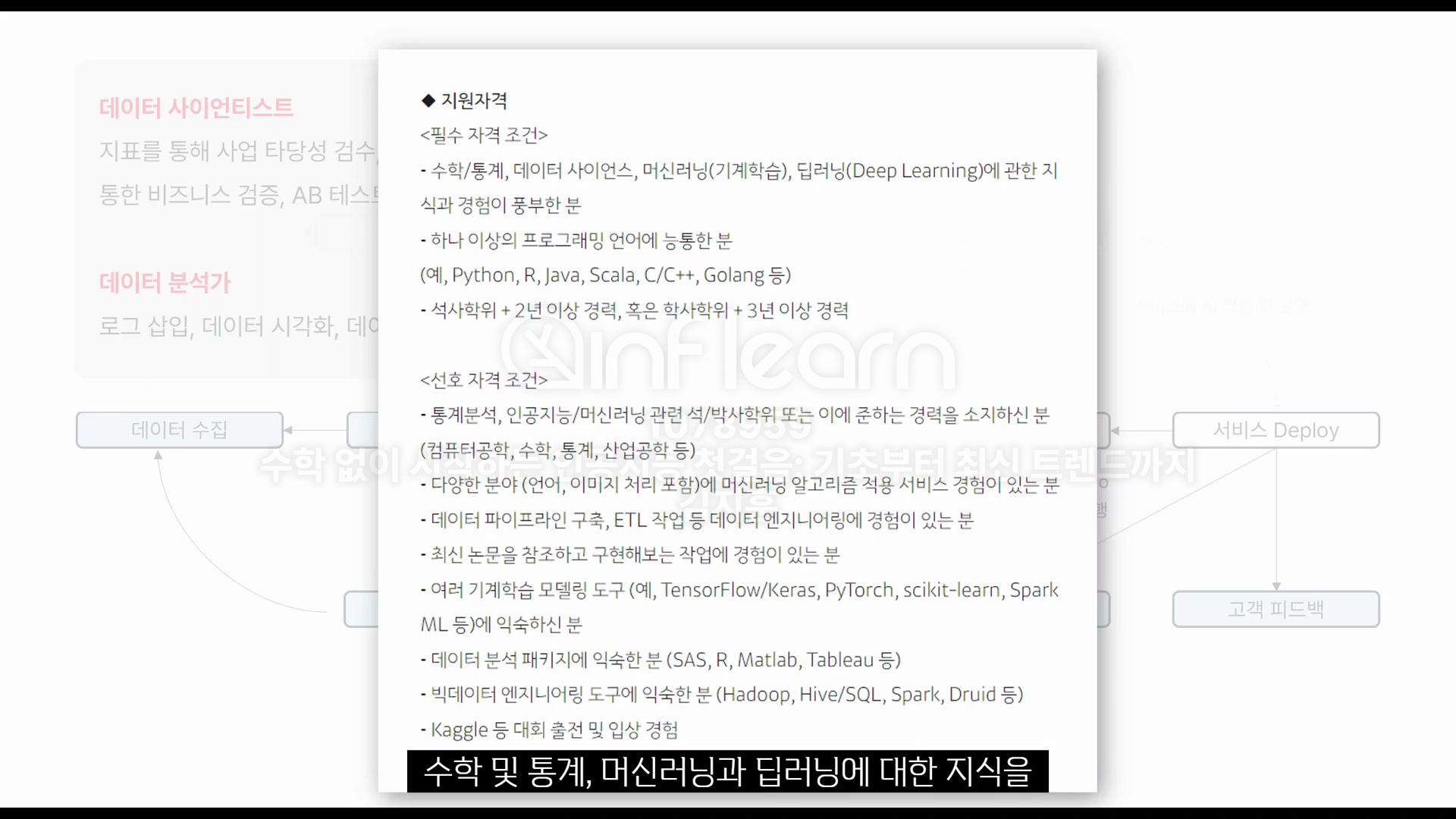
- 통계 지식, 데이터 엔지니어링, 논문을 읽을 수 있는 역량이 필요
데이터 분석가

- 로그 삽입 데이터 시각화
- 가공 / 정제 / 도표
- 데이터 로그 설계
데이터 엔지니어

- 데이터 파이프라인 설계
- 하둡 등 빅데이터 처리 역량
AI 연구원
- 논문 위주로 AI 모델을 개발함
- AI 학습 및 추론
MLOps
- 모델 배포, 운영, 모델 재학습, 모니터링 등 서비스에서 돌아가는 AI 모델 운영/관리
- 새로운 데이터 축적, 자동 모델 재학습
AI 지식이 있는 기획자 = AI PM
현재 내 직무다. 모델을 만드는 회사를 위해 데이터를 기획해주는 스타트업에서 일하고 있는데
이곳에서 AI PM이라는 직무를 처음 접했다. 전 운영 프로세스 전반을 수립하고 새로운 AI 서비스를 발굴한다
엔지니어와 함께 PoC를 진행한다.

- AI 서비스 플랫폼 기획, AI 니즈를 알고 프로덕트에 반영
데이터 프로덕트 기획자
- 머신러닝 기반 프로덕트 기획 경험
- AI 기반 신사업 방향성을 만듬
- 외부 전문기관과의 협업
- 트렌드도 잘 follow up하는 역량
5강 : 딥러닝은 항상 무적인가?
스팸 문자를 감지하는 모델에 대해 상상해보자. 딥러닝은 항상 무적일까?
- 머신러닝
- 감지 : 데이터를 모아서 사용한다
- 수집된 스팸 문자들을 레이블링을 진행한다 (피쳐 엔지니어링)
- 광고는 제목에서 유추가 가능한가?
- 광고는 본문에서 유추가 가능한가?
- 광고는 본문에 언제쯤 나오는가?
- 광고 키워드는 어떤게 나오는가?
- 머신러닝 알고리즘 개발
- XGBoost
- Random Forest
- K-Nearest Neighbor
- 스팸 문자 분류기를 개발, 실험을 진행, 고도화, 모델 학습을 진행함
- 완성된 모델에 새로운 데이터를 넣어 추론을 진행함
- 추론
- 딥러닝
- 수집
- 스팸 문자 데이터가 필요하다. 스스로 패턴을 수집하지만 머신러닝에 비해 많은 데이터를 필요로 한다
- 딥러닝 모델 개발
- 데이터 특징을 추출
- 추론
- 새 모델에게 새 문자를 보여주며 추론한다
- 자동차 번호판을 인식할 경우
- 변동성이 높지 않을 경우 머신러닝으로도 충분히 해결 가능하다. 또는 추가학습을 진행한다
- 딥러닝의 경우, 많은 데이터, 컴퓨터 리소스가 필요해서 금전적 어려움이 발생할 수 있다.
- 챗봇의 경우, 사람의 어순, 말투, 새로운 기능 추가, 지속적으로 서비스에 쌓이는 데이터
- 자연어 처리 문제 자체가 매우 어렵다. 문맥 파악의 어려움
- 한계가 명확하다
- 이럴땐 딥러닝을 사용한다!
- 수집
'Computer Engineering > AI' 카테고리의 다른 글
| chatgpt API를 활용하여 이미지 기반 응답 생성하기 (4) | 2024.12.02 |
|---|---|
| [쉽고 빠르게 익히는 실전 LLM] Ch1. LLM이란? (1) | 2024.08.21 |
| 벤치마크 데이터셋이란? (2) | 2024.08.14 |
| 의료 LLM의 발전에 대해서 (1) | 2024.07.16 |
| Data centric AI란? (0) | 2024.07.11 |