
서론
회사에서 크롤링하다가 정리해보고 싶어서 쓰는글..
1. 평소에 selenium이 동적 페이지 스크래핑하려면 최고다라고만 생각하다가 생각보다 셀레니움이 무겁고 또 엄청 느리다는 지적을 받음
또한 신뢰성 이슈가 있다기에 정리해보려고 함
2. selenium을 도커나 서버에서 띄울때 headless를 통해서 스크래핑이 가능함
3. 대안 찾아보기..
https://github.com/SeleniumHQ/selenium/issues
GitHub - SeleniumHQ/selenium: A browser automation framework and ecosystem.
A browser automation framework and ecosystem. Contribute to SeleniumHQ/selenium development by creating an account on GitHub.
github.com
Beautifulsoup과 Selenium의 비교
둘이 크게 다른 점이 있다면 먼저 동적인 페이지가 존재할 때 셀레니움은 버튼 클릭, 스크롤 조작등을 이용해 자바스크립트로 렌더링되는 데이터들도 가져올 수 있다는 장점이 있다.
Beautifulsoup
- HTML, XML 파일의 데이터를 추출하는 파이썬 라이브러리.
- 주로 requests, urlib를 이용해 HTML을 다운받아 텍스트로 변형하여 beautifulsoup의 내장 메소드(select_one, find, find_all)을 사용하여 데이터를 분류한다. (주로 태그로 분류함. ex: dev, div, span, td..)
- 서버사이드 렌더링을 사용하지 않는 사이트나 javascript 렌더링을 쓰는 사이트는 크롤링하기 빡세다.
Selenium
- javascript 렌더링으로 불러와지는 데이터를 버튼클릭, 스크롤 조작등을 사용하여 웹을 따라가며 데이터를 가져온다.
- WebDriver 프로토콜(ex: ChromeDriver, geckodriver, safaridriver)을 통해 크롤링하므로 실제 보여지는 웹 페이지의 전부를 가져올 수 있음
- 웹 브라우저를 직접 실행하기 때문에 속도가 느리고 메모리도 많이 차지한다.
- 멀티 프로세스를 사용해 여러 브라우저로 크롤링하는 방식으로 속도를 개선할 수 있다고 함.
- 주로 xpath를 사용해 페이지의 단일 element에 접근하는 방식 (beautifulsoup은 차례대로 태깅해서 들어감..-> 눈빠진다는 소리)
- find_element_by_* 메소드를 사용하면 HTML을 브라우저에서 파싱하기 때문에 굳이 beautifulsoup을 사용할 필요가 없음.
- 하지만 soup객체를 통한 편리한 이용이 필요하다면 driver.page_source 를 이용해서 브라우저의 HTML을 가져올 수 있다.
# 크롬 드라이버 headless 옵션 : 인터넷 브라우저창을 열지 않고 동작가능한 옵션
# webdriver.Chrome에 크롬 드라이버.exe를 저장한 파일 위치를 등록하여야 함
def chrome_options():
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('window-size=1920x1080')
options.add_argument("disable-gpu")
options.add_argument(f'user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36')
driver = webdriver.Chrome('/Users/Desktop/chromedriver', chrome_options=options)
return driverurl = "" # 크롤링하고 싶은 url 등록
driver = chrome_options() #headless 옵션 등록
driver.get(url) # url을 크롬드라이버로 접근
driver.implicitly_wait(time_to_wait=5) # 데이터를 불러오는 동안 타임wait
index, type, product = make_xpath() # 개발자도구 들어가서 xpath찾아서 등록해주기
# xpath에 해당하는 element 뽑아서 text 찾기
index_element = driver.find_element_by_xpath(basic_index).text
type_element = driver.find_element_by_xpath(type).text
product_element = driver.find_element_by_xpath(product_detail).text
driver.quit() # 크롬드라이버 종료개발자 도구에서 xpath 및 selector 찾는 법
첨 크롤링할때 이거 하는 법 몰라서 노가다했던 기억에 공유해봄.
1. 개발자 도구로 들어가서 왼쪽 상단에 네모에 화살표가 그려져있는 버튼 누르기
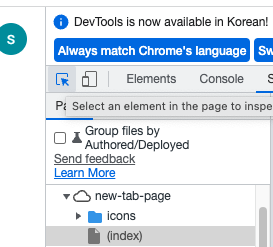
2. 누르면 마우스가 화살표처럼 변하는데 크롤링하고 싶은 텍스트 부분 눌러보기
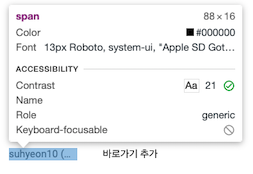
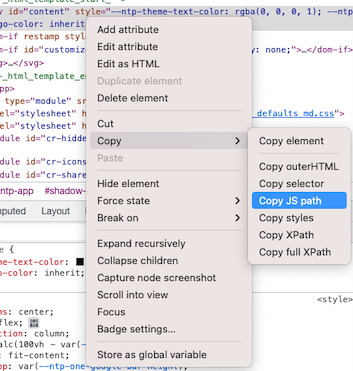
3. 코드 부분에서 오른쪽 마우스 클릭해서 원하는 거 카피하기
대안찾기
Selenium은 전체 브라우저를 실행하기 때문에 리소스를 많이 사용함 -> 헤드리스 브라우저 사용하는 것으로 해결 가능함
또한 신뢰할 수 없다는 평판이 있다. 셀레늄 테스트는 일반적으로 불안정하며 재현하기 어려운 불분명한 이유로 간헐적으로 실패한다.
- 임의 Timeout오류(요소가 나타날 때까지 충분한 시간을 기다리지만 표시되지 않습니다. )
- Random WebDriverException : can't access dead object
- 소켓 수준의 임의 시간 초과
- StaleElementReferenceExeption
- 요소가 표시되고 존재하며 클릭 가능하고 스크린샷에 표시되지만 로컬에서 작동하지 않지만 찾을 수 없습니다.
https://sqa.stackexchange.com/questions/32542/how-to-make-selenium-tests-more-stable/32544#32544
How to make selenium tests more stable?
I am using selenium tests to perform GUI-based system tests of non-public scientific use cases. Although I have build more-or-less a complete wrapper around the selenium module with functions to al...
sqa.stackexchange.com
그래서 찾아본 대안 2가지 -> playwrite, puppetier
기본적으로 두개 다 브라우저 자동화를 지원한다.
Playwrite
- 브라우저 자동화를 위한 Node.js 라이브러리
- 크로미움 기반의 브라우저, 파이어폭스, 사파리같은 Webkit 기반 브라우저를 지원 (선택적으로 브라우저를 선택하거나 여러 브라우저를 제공하는 서비스라면 매력적)
- 마이크로소프트에서 제공함 ( 업데이트가 빠름)
- 가장 큰 차별화 포인트는 브라우저 간 지원이다. Chromium, WebKit(Safari용 브라우저 엔진) 및 Firefox를 구동할 수 있음
https://playwright.dev/docs/intro
Installation | Playwright
Playwright Test was created specifically to accommodate the needs of end-to-end testing. Playwright supports all modern rendering engines including Chromium, WebKit, and Firefox. Test on Windows, Linux, and macOS, locally or on CI, headless or headed with
playwright.dev
Puppeter
- 부분적으로 브라우저와 인터페이스하기 때문에 브라우저 자동화가 더 쉽다.
- 셀레니움은 브라우저 사이에서 중개자 역할을 하는 웹 드라이버를 사용하는 반면 Puppeteer은 비표준 DevTools 프로토콜을 사용하여 크롬을 제어하므로 브라우저와 직접 통신하고 네트워크 요청 가로채기와 같은 추가 기능을 Selenium을 통해 제공
- 웹사이트 테스트와 TurboTax의 데이터 입력 자동화를 위해 Puppeteer을 사용함
참고
playwright test로 E2E 테스트 하기(vs. Cypress)
들어가기
junghan92.medium.com
https://velog.io/@zoeyul/webcrawling
Beautifulsoup vs Selenium vs Scrapy
HTML, XML 파일의 정보를 추출해내는 python 라이브러리python 내장 모듈일 requests나 urllib을 이용해 HTML을 다운 받고, beautifulsoup으로 테이터를 추출한다.서버에서 HTML을 다운 받기 때문에 서버사이드
velog.io
https://blog.logrocket.com/playwright-vs-puppeteer/
Playwright vs. Puppeteer: Which should you choose? - LogRocket Blog
Playwright and Puppeteer are both browser automation libraries for Node.js. Where they differ is in their browser support and potential long-term viability.
blog.logrocket.com
'Computer Engineering > Python' 카테고리의 다른 글
| 프리랜서를 위한 채용 공고 크롤링 및 카카오톡 공유 자동화 (1) | 2024.12.05 |
|---|---|
| python 패키지 관리 툴 Poetry 설정해보기 (0) | 2022.11.22 |