1. 건축물 데이터 가공하기
오늘은 건축물대장과 GIS건축통합정보를 연계한 건축물 데이터 통합 플랫폼을 만드는 과정을 기록하려 한다.
첫번째로, 건축물대장 데이터에서 강남역 대표 침수지역인 서초대로77,78에 관련된 데이터만 뽑은 뒤, 엑셀로 변환하는 작업을 하려고 한다.
건축물대장 데이터 보러가기
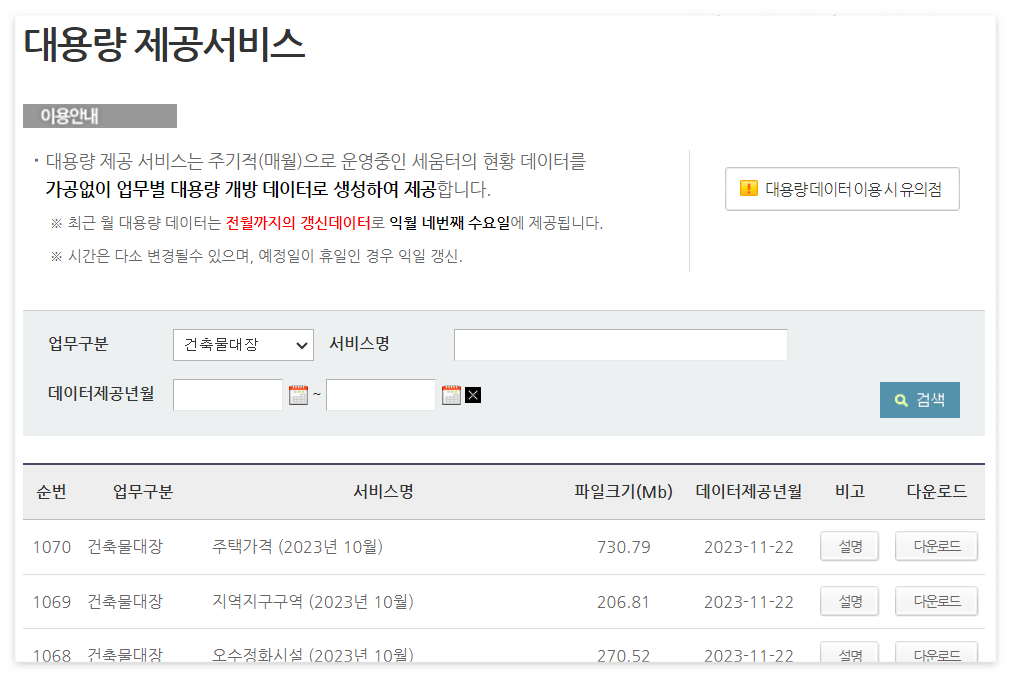
업무구분 > 건축물대장으로 검색한 뒤, 아래로 스크롤하면 다양한 데이터를 확인할 수 있다.
비고 > 설명 버튼을 누르면, 칼럼에 대한 내용을 엑셀로 다운받을 수 있다.
나에게 필요한 내용은 사용승인일, 건축물의 주용도, 지하층수, 면적 등 이었기 때문에 표제부를 선택해서 다운로드받았다.
다운받으면 txt파일로 내려오는데 이 파일을 Jupyter Notebook을 통해 정제하는 과정을 거칠 것이다.
칼럼과 데이터를 매칭해주어야하기 때문에 [설명]과 [다운로드] 버튼을 모두 눌러서 엑셀을 받아야한다.
다운받으면 아래처럼 두개의 파일을 얻을 수 있다.

주피터노트북으로 데이터 정제하기
윈도우 화면에서 주피터노트북을 검색하거나, CMD 화면에서 jupyter notebook 명령어로 주피터노트북을 실행한다.
나는 따로 폴더를 만들어서 진행했다.
오른쪽에 new 버튼을 눌러서 폴더를 만들거나 .ipynb 파일을 생성할 수 있다.
.txt 파일을 읽은 뒤, 칼럼과 매칭하기
import pandas as pd
# 파일 경로를 알고 있다면 사용
file_path = "C:/Users/82104/k-pass/mart_djy_03.txt"
# 각 칼럼에 대한 데이터 타입 지정
dtype_mapping = {
'관리_건축물대장_PK': str,
'대장_구분_코드': str,
'대장_구분_코드_명': str,
'대장_종류_코드': str,
'대장_종류_코드_명': str,
'대지_위치': str,
'도로명_대지_위치': str,
'건물_명': str,
'시군구_코드': str,
'법정동_코드': str,
'대지_구분_코드': str,
'번': str,
'지': str,
'특수지_명': str,
'블록': str,
'로트': str,
'외필지_수': 'Int64',
'새주소_도로_코드': str,
'새주소_법정동_코드': str,
'새주소_지상지하_코드': str,
'새주소_본_번': 'Int64',
'새주소_부_번': 'Int64',
'동_명': str,
'주_부속_구분_코드': str,
'주_부속_구분_코드_명': str,
'대지_면적(㎡)': 'float',
'건축_면적(㎡)': 'float',
'건폐_율(%)': 'float',
'연면적(㎡)': 'float',
'용적_률_산정_연면적(㎡)': 'float',
'용적_률(%)': 'float',
'구조_코드': str,
'구조_코드_명': str,
'기타_구조': str,
'주_용도_코드': str,
'주_용도_코드_명': str,
'기타_용도': str,
'지붕_코드': str,
'지붕_코드_명': str,
'기타_지붕': str,
'세대_수(세대)': 'Int64',
'가구_수(가구)': 'Int64',
'높이(m)': 'float',
'지상_층_수': 'Int64',
'지하_층_수': 'Int64',
'승용_승강기_수': 'Int64',
'비상용_승강기_수': 'Int64',
'부속_건축물_수': 'Int64',
'부속_건축물_면적(㎡)': 'float',
'총_동_연면적(㎡)': 'float',
'옥내_기계식_대수(대)': 'Int64',
'옥내_기계식_면적(㎡)': 'float',
'옥외_기계식_대수(대)': 'Int64',
'옥외_기계식_면적(㎡)': 'float',
'옥내_자주식_대수(대)': 'Int64',
'옥내_자주식_면적(㎡)': 'float',
'옥외_자주식_대수(대)': 'Int64',
'옥외_자주식_면적(㎡)': 'float',
'허가_일': str,
'착공_일': str,
'사용승인_일': str,
'허가번호_년': str,
'허가번호_기관_코드': str,
'허가번호_기관_코드_명': str,
'허가번호_구분_코드': str,
'허가번호_구분_코드_명': str,
'호_수(호)': 'Int64',
'에너지효율_등급': str,
'에너지절감_율': 'float',
'에너지_EPI점수': 'float',
'친환경_건축물_등급': str,
'친환경_건축물_인증점수': 'float',
'지능형_건축물_등급': str,
'지능형_건축물_인증점수': 'float',
'생성_일자': str,
'내진_설계_적용_여부': str,
'내진_능력': str
}
# 파일을 DataFrame으로 읽기
df = pd.read_csv(file_path, names=dtype_mapping, sep='|', encoding='cp949', dtype=dtype_mapping)
# 데이터 확인
print(df.head())
나는 pandas 라이브러리를 사용해 파일의 절대경로에서 텍스트 파일을 읽은 뒤, DataFrame으로 변환하는 작업을 진행했다.
텍스트 파일을 열어보니, 데이터를 '|'를 사용하여 구분되어 있어서 데이터를 분리한 뒤 칼럼과 매칭했다.
- pd.read_csv() : 텍스트 파일을 읽은뒤, DataFrame으로 변환하는 메소드
- file_path : 읽을 파일의 경로
- name=dtype_mapping : 칼럼의 이름을 지정하고, 데이터 타입 매핑에 사용한다.
- sep= '|' : 파일 내에서 열을 구분하는 구분자를 지정한다.
- encoding='cp949' : 파일의 인코딩을 설정. UTF-8은 오류가 발생한다
- dtype=dtype_mapping : 각 열에 대한 데이터 타입을 미리 정의
- print(df.head()) : 데이터프레임의 첫 5개의 데이터를 출력한다.
서초구 데이터와, 서초대로77/78 데이터를 분류한 뒤 엑셀로 export하기
filtered_df = df[df['대지_위치'].str.contains('서초구')]
print(len(filtered_df))
print(filtered_df.head)
filtered_df.to_excel('표제부_서초구.xlsx', index=False)
filtered_df2 = filtered_df[filtered_df['도로명_대지_위치'].str.contains('서초대로77|서초대로78', na=False)]
print(len(filtered_df2))
print(filtered_df2.head)
filtered_df2.to_excel('표제부_서초구_서초대로.xlsx', index=False)
위에서 생성한 DataFrame에서 특정 조건을 만족하는 행들을 필터링하고 결과값을 엑셀 파일로 저장하는 작업을 수행했다.
- filtered_df = df[df['대지_위치'].str.contains('서초구')] : '대지_위치' 칼럼에서 '서초구' 단어를 포함하는 모든 행을 필터링
- df['대지_위치'].str.contains('서초구') : '대지_위치'열의 각 값에 대해 '서초구'가 포함되었는지 여부를 검사
- df[df['대지_위치'].str.contains('서초구')] : 이 조건을 만족하는 행들을 선택한뒤 filtered_df에 저장
- print(len(filtered_df)) : 데이터 수를 출력
- filtered_df.to_excel('표제부_서초구.xlsx', index=False): filtered_df : '표제부_서초구.xlsx' 엑셀파일로 저장.
- index=False : df의 인덱스를 엑셀파일에 저장하지 않음
- filtered_df2 = filtered_df[filtered_df['도로명_대지_위치'].str.contains('서초대로77|서초대로78', na=False)]
- '서초대로77' 또는 '서초대로78'이 포함되어 있는지 여부를 검사한다
구글 드라이브를 통해 위도, 경도 데이터 찾은 뒤 엑셀에 넣기
카카오맵에 핀을 꼽거나 영역을 표시하려면 위도,경도 데이터가 필요하다.
이를 위해서 구글 드라이브를 사용했다.
구글 드라이브에 파일을 업로드한 뒤, 파일 > 구글시트로 저장을 누른다.

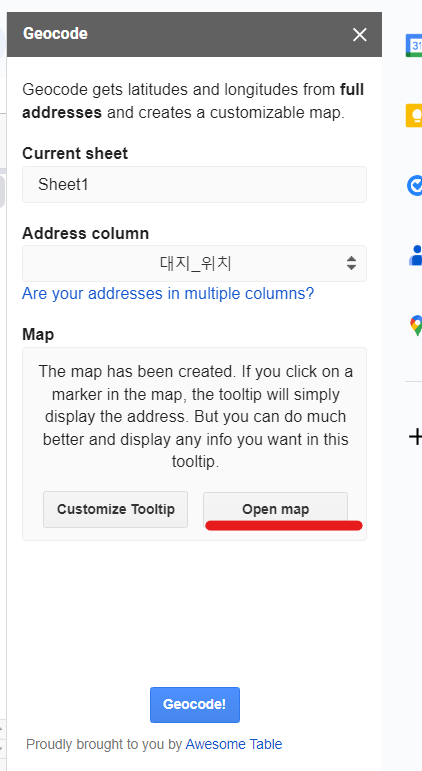
우측에 있는 + 버튼을 누른뒤, Geocode by Aweso를 설치한다.
설치가 완료되면 확장 프로그램 탭이 생성된다. 확장 프로그램 > Geocode by Awesome Table < Start Geocoding 을 누른다.
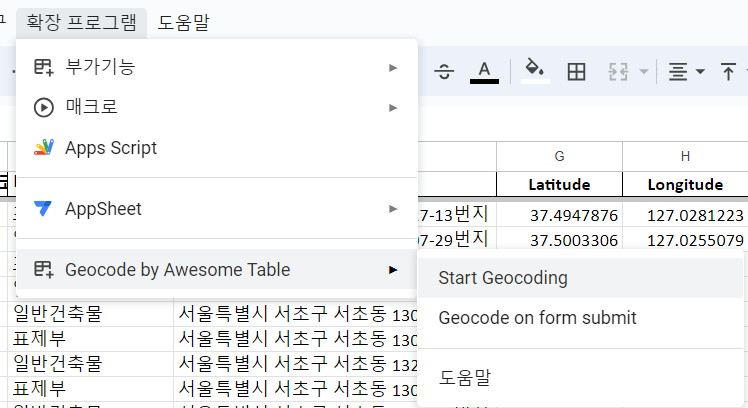
오른쪽에 탭이 생성되는데 주소가 적힌 칼럼을 선택한뒤 start 버튼을 눌러주면 된다.
그러면 주소 칼럼 옆에 위도, 경도 데이터가 자동으로 생성되는 것을 확인할 수 있다.
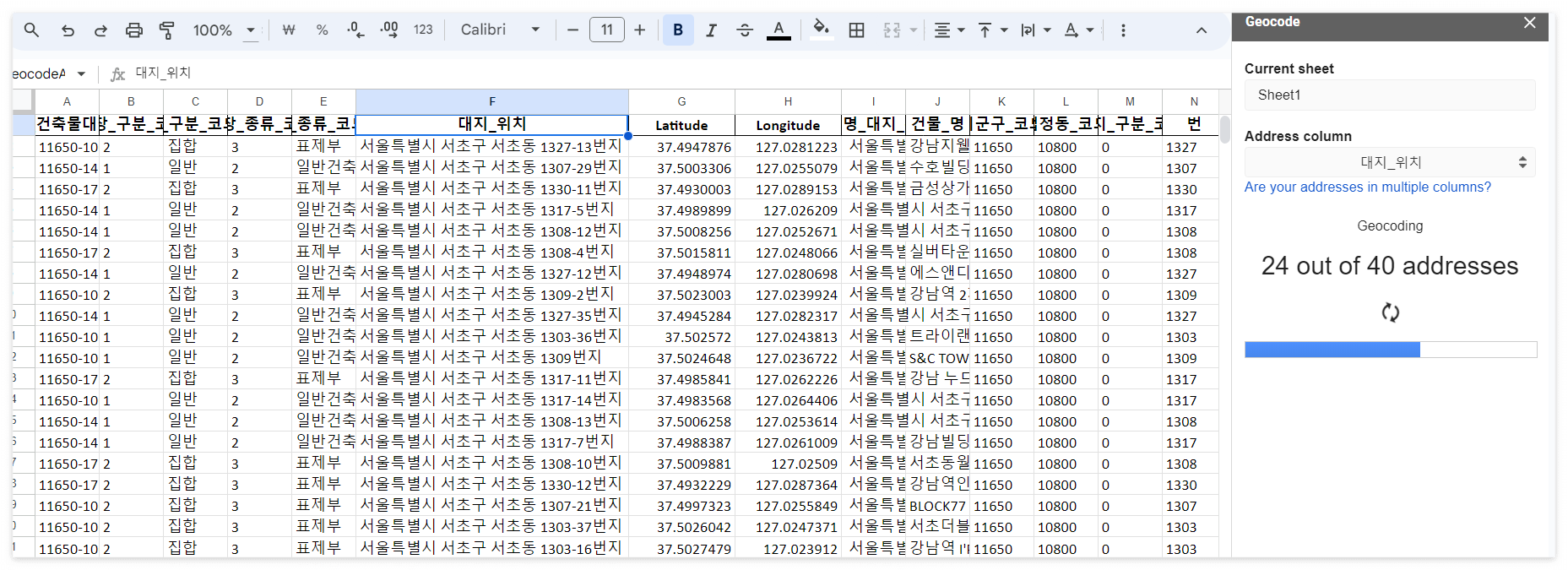
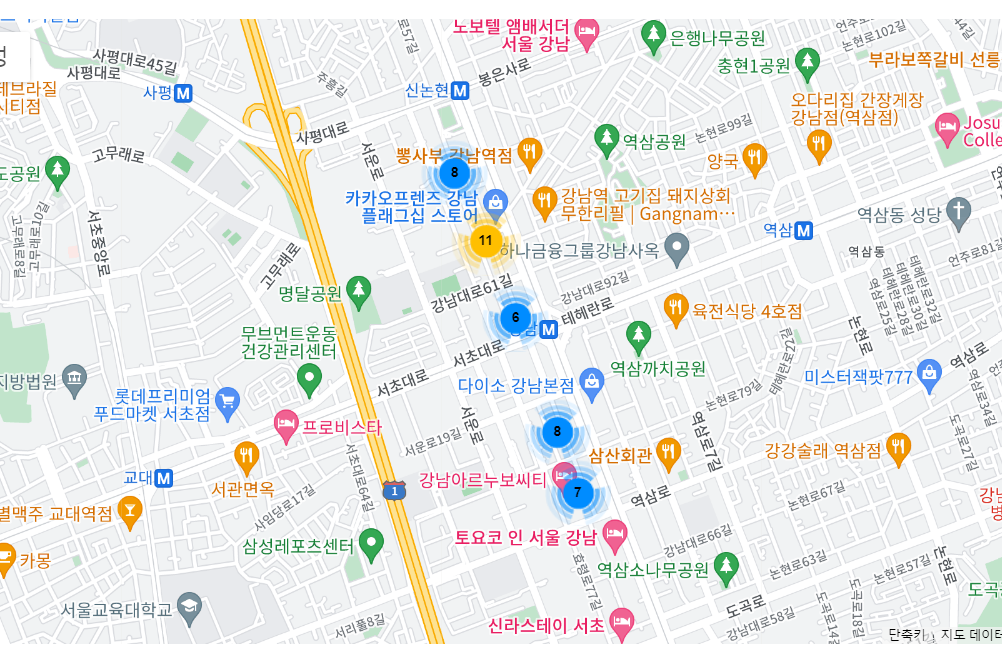
데이터 위치를 지도로 확인해보기
이렇게 위도/경도를 생성하고 나서는 지도에서 확인해볼 수도 있다. 아래 탭에서 open map 버튼을 눌러보자.